Lokka 0.1.0をリリースしました。これはPyhaからLokkaに名前が変わってから最初のリリースです。
ダウンロードはこちらから。
PyhaはPython製であるように見えてしまって紛らわしい説があった(あたりまえ)のでGoogleグループで投票で新しい名前、Lokka(ロッカ)になりました。
公式サイトもlokka.orgになりました。改めて調べてみると北欧の地名?ってPyから始まるものが結構多いんですよね。Pythonのソフト作るときにいいかもです。
Lokka 0.1.0をリリースしました。これはPyhaからLokkaに名前が変わってから最初のリリースです。
ダウンロードはこちらから。
PyhaはPython製であるように見えてしまって紛らわしい説があった(あたりまえ)のでGoogleグループで投票で新しい名前、Lokka(ロッカ)になりました。
公式サイトもlokka.orgになりました。改めて調べてみると北欧の地名?ってPyから始まるものが結構多いんですよね。Pythonのソフト作るときにいいかもです。
msakamoto-sfさんからマルチプラットフォームで外部プロセス実行とそのプロセスとのプロセス間通信が簡単にできるQProcess(Qt)を教えてもらったので勉強の為にCUIアプリのSayKanaをQtのGUIアプリから叩くqtalk.appというのを作ってみました。
komagata's qtalk at master - GitHub
#include <QApplication>
#include <QMainWindow>
#include <QLabel>
#include <QPocess>
#include <QTextCodec>
int main(int argc, char *argv[]) {
QApplication app(argc, argv);
QTextCodec::setCodecForCStrings(QTextCodec::codecForLocale());
QMainWindow mainWindow;
mainWindow.setWindowTitle("QTalk");
mainWindow.resize(200, 30);
mainWindow.show();
QProcess process;
process.start("/usr/bin/env SayKana -s 70 なにかすごいきのうがあるとおもったの?。ばかなの?。しぬの?");
return app.exec();
}しかしTerminalから
% open qtalk.appみたいに実行すると動くんですが、Finderから起動すると動きません。GUIアプリからCUIコマンドを実行するには普通どうするんでしょうか・・・?
2010月10日10追記:
/usr/local/bin/SayKanaとしたらFinderからでも動きました。/usr/local/bin/saykanaだと上記の状態になってました。僕のzshの設定のせいっぽいです。
newしないでクラス変数ってどうやってテストするのかな?と思ってたら貰ったパッチに書いてあった。
class Foo
@@foo = 'foo!'
end
puts Foo.send(:class_variable_get, '@@foo') # foo!なるほどー、これは簡単!
pyhaのGUIランチャー(一般の方やデザイナーの方には黒い画面必須はありえないから)を作ろうとしてるんですが、コードベースが共通でwindows, mac, linux対応のGUIランチャーを作るとすると何を使えばいいのか悩んでました。やはり各種環境でネイティブの見た目がいいということでQtを使い始めたんですが、そもそも各種環境で共通のやり方で外部プロセス(要はruby pyha.rb)を実行するやり方がよく分かりませんでした。
よく考えたらforkが出来ないってのはMinGWとか使えば解決じゃんということに考えが至りませんでした。とにかく「Windowsではforkが使えない」という先入観にやられてました。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
char cmd[] = "ruby -e \"puts 'ruby!'\"";
system(cmd);
return 0;
}Windows(MinGW), Mac OS X, Linuxで上記のコードはフツーに動きました。何と素晴らしいんでしょう!
Qtの方は単なるランチャーで対したことしないのでそれ程大変じゃ無さそうです。(アイコンをどうやって設定するのかぐらい?)
ただ、そのGUIランチャーを同伴すると、Qtのライセンス(GPLv3 or LGPL)の影響でPyhaがMITライセンスで居られなくなるのかもしれません。どうなんだろう?
※pyhaはlokkaに名前が変わりました。公式サイトのURL、リポジトリの場所もかわりました。
貧弱一般プロジェクト(@ブロントさん)であるpyhaですが、もし興味があるという方ががいれば分り易いようにコードが大体どんな感じなのか書いておこうと思います。(pyhaは名前を見たら殆どの人はpython製だと思うということに大分後になって気付きました・・・)
基本、sinatra, datamapper, hamlです。あとは動かすためのbundlerです。
ファイルレイアウトはいわゆるsinatraの"Moduler"スタイルで、sinatraやったことがある人だったら、「ああ、コレか・・・」ってなもんです。
Gemfile --- bundlerが読む必要なgemの一覧
config.ru --- rackサーバーが最初に見るファイル
lib/
pyha.rb --- 今のところ特に何もしない
pyha/ --- 基本全部この中。将来的にはgemの中に入るハズ
app.rb --- 中心部分。ここ見りゃ大体わかる
helpers.rb --- rails風のヘルパー以外にapp内でのユーティリティも含む
before.rb --- リクエストされたときの前処理
entry.rb --- DataMapperのモデル。他にもいくつかある。
public/ --- ドキュメントルート
admin/ --- 管理画面
system/ --- エラーとかシステムで使うテンプレ
theme/ --- テーマ。現状テーマ名=この下のディレクトリ名
default/ --- デフォルトテーマ。erbでWordPress経験者のデザイナーに優しくをモットーに。
p0t/ --- docs.komagata.orgのテーマ。hamlでなるべくDRYに書く。プログラマー向け。
plugin/ --- プラグインはsinatra extensionのサブセット
hello --- plugin以下のディレクトリ名=プラグイン名
lib/ --- 各プラグインディレクトリ以下はgem化を見越してgemのレイアウト準拠
pyha/ --- 一応、pyhaネームスペース以下にする
hello.rb --- Pyha::プラグイン名というclass or moduleが読み込まれるという決まり
普通のModulerスタイルにhelpersとbeforeを別ファイルにしたってだけです。
テーマ(テンプレートの集合)はWordPressでテーマを作ってるようなデザイナーを想定していて、そういう人がWordPressより一貫した分り易いsyntaxで簡単に書けるように注意しています。
entries.erb(必須) --- 複数のエントリを表示するテンプレート
entry.erb(必須) --- 1個のエントリを表示するテンプレート
layout.erb --- 外枠を表示するテンプレート
index.erb --- トップページを表示するテンプレート
search.erb --- 検索結果を表示するテンプレート
category.erb --- カテゴリー別エントリ一覧を表示するテンプレート
tag.erb --- タグ別エントリー一覧を表示するテンプレート
yearly.erb --- 年別エントリー一覧を表示するテンプレート
monthly.erb --- 月別エントリー一覧を表示するテンプレート
style.css --- CSS(読み込める場所にあればどこでもいい)
screenshot.png --- テーマ選択画面に表示される画像
必須のモノ以外はそのファイルが存在する場合はそちらを優先するようになっています。例えばentries.erbとindex.erbが両方あったらトップページにアクセスした場合、index.erbが表示されます。また、テンプレ無いでのpartialは好きに出来るのでheader.erbとかfooter.erbとか好きに作れます。また、erb, haml, erubisの3種類のテンプレートが使え、拡張子で判断されます。erb, haml, erubisの順に優先度があり、entry.erbがあるとentry.hamlは使われません。
モデルはDataMapperのをそのまま使っています。自動的にテーマデザイナー向けAPIに一貫性が出来ます。
entry --- エントリー。サブクラスは増える可能性あり
post --- 投稿。pageとの違いは各種テンプレにデフォルトでassignされてるかどうかだけ(例:@posts)
page --- ページ。CMS的に好きなページを作る場合に使う
site --- このサイト/ブログ自体の情報
user --- ユーザー。そんなに使わない
category --- ツリー構造を持つ。エントリが持つcategoryはひとつだけという制約があるのはパンくずリストを生成するため
tag --- categoryの制約が無い。パンくずリストが無ければtagだけでも問題無いんだが・・・
comment --- いわゆるコメント。どうせdisqusとか使うだろうと思って軽視していた
WordPressに比べてApache, MySQLが要らないので何気にRubyはWindows環境に向いている。
とにかく誰でもwelcomeです。「インストールした」ってブログに書いていただけるだけでもありがたいです。
基本、コード書いてやってもいいという方にはgithubのコラボレーター権限をホイホイ渡しますのでチマチマpull requestが面倒な方はMLやtwitterでおっしゃってください。
最近のトラックパッドに付いてるマルチタッチのジェスチャー(スワイプダウンとか)をFirefoxで使う場合、今までMultiClutchというソフトを使ってたんですが、Firefox3.5からはFirefoxだけで設定できるようになってるそうです。
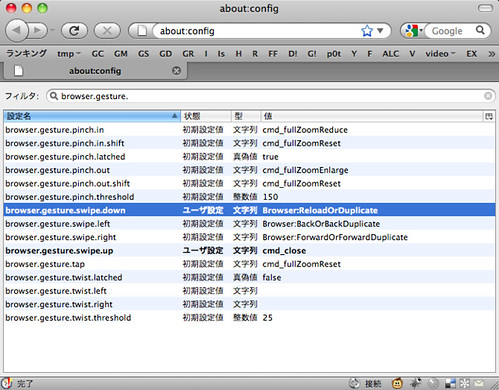
"スワイプダウン"に"リロード"、"スワイプアップ"に"タブを閉じる"を設定しています。これが無いとダラダラインターネットできなくなって困る。
PyhaLokkaにMLを作りました。
僕一人ではすごく悲しい雰囲気になってしまうのでサクラでいいので入ってください・・・。
ブログってフレームワークのHello world的な扱いで出てくるぐらいなので誰でも作れます。逆に言うと技術的なチャレンジは少なく、どれだけ手を動かせるか的なところがあってプログラマー的には面倒です。だからあまりエッジな人は作りませんよね。あるとすればミニマリストのための超シンプルツールで、これは作ってて楽しい。僕も以前、普通に作り始めたらそうなってしまって、一般ユーザーやデザイナーがWordPressに求めてるようなものは出来ませんでした。
PHP以外で一般ユーザーやデザイナーにも普及するWebアプリなんて無理なんだと諦めていましたが、RedmineはWeb制作会社にいるデザイナーに何人か聞いたら結構な割合で知ってました。なんだ、Rubyでも行けるんじゃん。
「なんで僕らは仕事で、自分のブログで、WordPressを使ってるんだ?Rubyでそういうのが無いのはおかしい!」
そんなよく分からない義務感?が開発の原動力になっていて、元々そういうツールがあればそれを使いたいし、その開発に参加すれば良いと思っています。しかし上記の様な事情があってあまり作りたがる人はいません・・・。
※Radiant CMSは僕的に設計やコードは素晴らしくて若干うっとりしたぐらいです。しかしデザイナーに聞くと、本当に欲しいのは純粋なCMSではなく、ブログツールベースのCMSであるようなのです。
PyhaLokkaはSinatraベースのまだまだ未熟なブログツールなので、Rubyがわかれば誰でもコーディングの余地がいくらでもあります。(例えば投稿した後にflushで「投稿しました」とか出すべきなのを出してないとか、helperその他はpadrinoのモジュールに置き換えたいとか、テストが無いとか・・・)
貧相なプロジェクトの割にWordPress打倒!という分り易くも無茶な目標を掲げてやっていくのは面白いかもなあと最近思いはじめました。
「みんな、オラに力(コード)を分けてくれ!」
作ってる人のためのプロフィールサービス"MAKES THIS"にAPI作りました。jsonでプロフィール情報を返します。/profiles.jsで一覧、/名前/profile.jsで個別にって感じです。
MAKES THISはTHE SETUPのパクりです。THE SEUPみたいにインタービューに答える風で書いてみてください。
DataMapperのvalidationエラーのメッセージを国際化するdm-validations-i18nというgemを作りました。
komagata's dm-validations-i18n at master - GitHub
require 'rubygems'
require 'dm-core'
require 'dm-migrations'
require 'dm-validations'
require 'dm-validations-i18n'
DataMapper.setup(:default, 'sqlite::memory:')
class Employee
include DataMapper::Resource
property :id, Serial
property :name, String
validates_presence_of :name
end
DataMapper.auto_migrate!
# here!
DataMapper::Validations::I18n.localize! 'ja'
puts Employee.create.errors.firstNameを入力してください。
取り急ぎMAKES THISとLokkaで必要だったのでスイマセン・・・。
言語ファイルさえあればen, ja以外もすぐ対応します。翻訳内容はgettext_activerecordからほぼお借りしました。

最近、PSPでゲームのダウンロード購入をちょこちょこしてます。アーカイブスのゲームが2〜3本しか入らないので16GBのメモリースティックを買いました。
PSP買ったのが昔なので今まで使ってるのが何GBなのか忘れてましたが交換するとき見てびっくり。1GBしかなかったのか・・・。